エリック・エヴァンスのドメイン駆動設計 を読んで
全体の感想
理解の難易度が高めで分量が多い。
難しい理由の一つはコードを交えた具体例がほぼ無い事かと思われる。 実践ドメイン本やDDDやってみた系のリポジトリを参考にしつつ読むと良いかもしれない。
継続的なリファクタリングやドメインエキスパートとのコミュニケーションで コアとなるドメインモデルを改善する事が最も重要だという事が繰り返し述べられている。
幾つかの定義された語句はDDD本を読んだ人の中で一般教養的に使える可能性が高く
DDDで言う所のXXXみたいな感じで通じると思われるので抑えておいて損は無いはず。
エッセンス抜粋
幾つか語句説明やエッセンスを抜き出して雰囲気を伝える*1
・ユビキタス言語 開発者とドメインエキスパートが同じ意味の用語を設定し利用し齟齬を防ぐ ・モデル駆動設計 モデリングと実装を完全に作業分担すべきでない コードを通してモデルを表現する必要が有る ・エンティティと値オブジェクト エンティティは識別可能でユニークなもの(特定のユーザー等) 値オブジェクトは不変で変更管理を必要としないもの(性別とか日付等) 値オブジェクトは可変にするより別の値オブジェクトを作成する方がシンプルに実装可能 ただし大量の値オブジェクトを生成する時はリソースに注意 ・サービス 引数と結果がドメインオブジェクト ドメインモデルのインターフェイスを持つ それ自体は状態を持たない アプリケーション層でドメインモデルが相互動作する ・集約、ルートエンティティ 境界内の他エンティティを参照し境界内の不変条件をチェックする責務を持つ ・リポジトリ データベースとのやりとり等 情報の永続化 トランザクションはクライアントで実施 インスタンス生成はファクトリに委譲しリポジトリと組み合わせない方が良い ・コアドメイン ビジネスの本質、長期的なリソースを集中すべき ・汎用サブドメイン 汎用的なモデル、実装に事前知識が要らない、短期的リソースを割当てる事も可能 ・大規模な構造 フレームワーク的なもの。 レイヤ化は成功しやすい手法(実装上のデザインパターンではなくドメインモデル上のレイヤ分けが紹介されていた) ・アーキテクチャの作り方 複数のアプリケーションチームが共同で作るパターン アーキテクトチームが先導するパターン(ただしアプリケーションチームの実装を妨げない事が重要)
おすすめ読者層
良いソフトウェア設計とは何かを学びたい人(初学者以外)
モデリングの考え方を深めたい人
Clean Architecture読了した人
雑感
- 正直理解しきれていない部分が多々有るので読み返したり引き続き理解を深める必要が有りそう

- 作者: Eric Evans
- 出版社/メーカー: 翔泳社
- 発売日: 2013/11/20
- メディア: Kindle版
- この商品を含むブログ (8件) を見る
*1:個人的解釈なので真偽は保証しない
Clean Architecture 達人に学ぶソフトウェアの構造と設計 を読んで
全体の感想
事前の予想ではもっとテクニカルな内容かと思っていたが、大部分は筆者の50年に及ぶ経験(!)に基づく良いアーキテクチャの原則が語られている。
ちょっと昔話が多い気もするが体験談形式なので技術面のハードルが高い訳ではなく読みやすい。
・重要なビジネスロジックを上位の方針として分離しそれを中心に開発する ・フレームワークやDB入出力を含む実装は下位レベルの詳細として上位ロジックに依存させる ・依存性の方向をコントロールする ・コンポーネントの境界を意識する
大部分は上記の様なクリーンアーキテクチャの基本原則を様々なプロジェクトの成功や失敗の体験談を通して語っている。
技術面
技術的原則で触れられていたのは以下辺り。*1
・単一責任の原則 ・オープン、クローズドの原則 ・リスコフの置換原則 ・インターフェース分離の原則 ・依存性関係逆転の原則 ・閉鎖性共通の原則 ・再利用、リリース等価の原則 ・全再利用の原則 ・非循環依存関係の原則 ・安定依存の原則 ・安定度、抽象度等価の原則
おすすめ読者層
良いソフトウェア設計とは何かを学びたい人
局所的なコーディング業務しか携わっていないが全体のアーキテクチャに対して理解を深めたい人
Web系開発に限定されず組み込み開発や他の分野のソフトウェアエンジニア
印象に残った内容
1966年に関数呼び出しスタックをヒープに移動出来る事を発見した事がオブジェクト指向の原理に繋がっている
抽象に依存せよ(依存と抽象度のグラフ等)
1960年代の38インチ ストレージ ディスクがもし緩んで飛び出すと壁を突き破る可能性が有ったw
雑感
設計力は急に伸びないので常に意識して積み上げる必要が有る
DDDも読まないと。。

Clean Architecture 達人に学ぶソフトウェアの構造と設計
- 作者: Robert C.Martin,角征典,高木正弘
- 出版社/メーカー: KADOKAWA
- 発売日: 2018/07/27
- メディア: 単行本
- この商品を含むブログを見る
*1:色々な所で語られている基本原則
Dockerで開発環境構築 Ruby on Rails編
目的
気軽に使えるローカル開発環境としてDockerでRuby on Railsをセットアップしてみた。
設定ポイントや気になった事を書き留める。
後学の為にMySQLユーザー権限変更やDB文字コード指定したり環境変数ファイル切り出したりしている。
環境
作成内容はGitHubにアップしておいた。 (railsディレクトリが該当) github.com
docker-compose.yml
version: '3' services: app: build: ./myapp command: bundle exec rails s -p 3000 -b '0.0.0.0' env_file: ./config/myapp/.env environment: TZ: "Asia/Tokyo" volumes: - ./myapp:/myapp ports: - "3000:3000" links: - db db: build: ./mysql env_file: ./config/mysql/.env environment: TZ: "Asia/Tokyo" volumes: - ./mysql/data/:/var/lib/mysql - ./mysql/logs/:/var/log/mysql - ./mysql/init/:/docker-entrypoint-initdb.d ports: - "3306:3306"
DBのアカウント情報は.envに分離してみた。
docker-entrypoint-initdb.dにMySQL追加ユーザーへのDB作成権限を付与するシェルスクリプトを共有。
Dockerfile
ruby側
FROM ruby:2.5.1 ENV LANG C.UTF-8 RUN apt-get update -qq RUN mkdir /myapp WORKDIR /myapp COPY Gemfile /myapp/Gemfile COPY Gemfile.lock /myapp/Gemfile.lock RUN bundle install
Gemfileで rails導入。
gem 'rails', '5.2.0'
utf8mb4指定
MySQL 5.7.9以上ならばデフォルト状態でutf8mb4指定可能。
5.7.9未満ならMySQL設定で必要に応じて変更する。
[参考] Rails(ActiveRecord)とMySQLでutf8mb4を扱う設定 - Qiita
シェルスクリプト
シェルで簡単立ち上げ可能。
コンテナ初期化。*1
% bash init_container.sh
Railsでmigration情報作成後に以下でサービスアップ。
% bash up_service.sh
動作確認
コンソールから適当にデータ投入してみる。
% docker-compose run --rm app rails generate scaffold user number:integer name:string % docker-compose run app rails console
user = User.new(number: 1, name: "Ruby on Rails") user.save
ブラウザからアクセスする。
http://localhost:3000/users
{"id":1,"number":1,"name":"Ruby on Rails","created_at":"2018-09-08T19:02:06.000Z","updated_at":"2018-09-08T19:02:06.000Z"}]
成功。
Dockerで開発環境構築 MySQL編
目的
気軽に使えるローカル開発環境としてDockerでMySQLをセットアップしてみた。
設定ポイントや気になった事を書き留める。
環境
作成内容はGitHubにアップしておいた。 github.com
docker-compose.yml
version: '3' services: db: build: ./mysql env_file: ./mysql/.env environment: TZ: "Asia/Tokyo" volumes: - ./mysql/data/:/var/lib/mysql - ./mysql/logs/:/var/log/mysql ports: - "3306:3306"
Dockerfile
FROM mysql:5.7 RUN apt-get update RUN apt-get install -y vim # not root user RUN useradd mysql_user USER mysql_user # add custom.cnf COPY config/*.cnf /etc/mysql/conf.d
USERを指定した。
MySQLプロセスもコンテナも指定したユーザー権限で動作する模様。
(USER指定無しの場合はMySQLはmysqlプロセス、コンテナ自体は root権限で動作する。)ADDとCOPYはどちらも使えるけどADDはファイルコピー以外の機能も有るから、 単にファイル配置ならCOPYがシンプルで良いらしい
ユーザー権限
デフォルトではコンテナ自体はroot権限で動作する。
ローカル開発環境と割り切ればそれで問題無いのかも。
Docker のセキュリティ — Docker-docs-ja 17.06.Beta ドキュメント
もしくはuseraddしてsudo出来る状態にしているパターンも見かける。
(この場合dockerファイルにパスワードが書いてあったりするけど問題無いのだろうか)
この辺りは折を見て追調査していきたい。
MySQL cnf設定
MySQLの設定を幾つか実施してみた(詳しくはアップしているcnfファイルを確認してください)。
開発環境としては最低限以下を設定しておけば良さそう。
[mysql] default-character-set=utf8mb4 [mysqld] character-set-server=utf8mb4 collation-server=utf8mb4_bin [client] default-character-set=utf8mb4
SQLクライアントから接続
MySQL Workbenchから接続してみた。
127.0.0.1:3306に接続。
アカウント情報は.envで指定した内容。
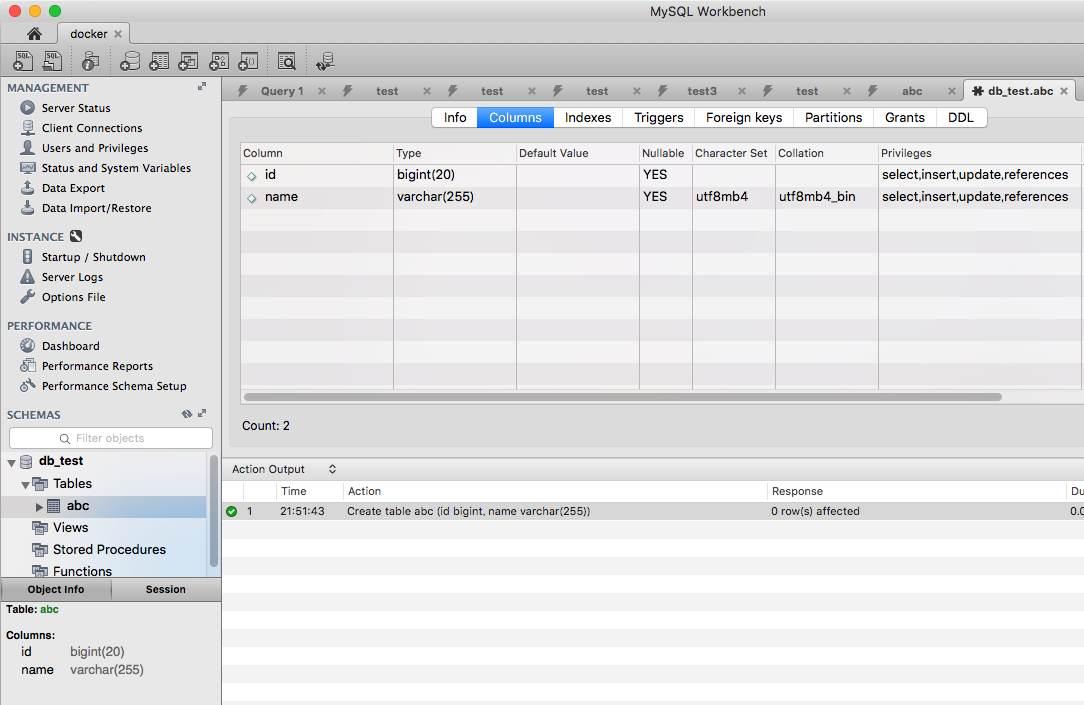
適当にテーブルを作成、Character Set とCollationが指定通りになっている事が確認出来る。
以上
リファクタリング―既存のコードを安全に改善する― を読んで
はじめに
継続的にソフトウェアを改善するにはリファクタリングは欠かせないタスクである。
自分でも意識してリファクタリング作業は行っているが改めて体系的に纏まった情報を確認する事にした。
全体の感想
リファクタリングは多岐にわたる条件や構成の元で行う場合が多く端的な説明が難しいと思われるが、数ページ単位にまとめられた構成でリファクタリング技法が紹介されておりシンプルに理解しやすい。
各リファクタリング技法は以下の様に構成されており全体から詳細へと読み進める事が出来る。
クラス図 or 概要コード ↓ 動機 ↓ 手順説明 ↓ コード例
その他にはリファクタリングを実施すべき時を知らせる”コードの不吉な臭い”や、開発現場でのリファクタリングに対する動機付け等についても記述されている。
おすすめ読者層
リファクタリングスキルを向上させたい人
効果的な指摘をしてもらえるレビュアーがいない人
非効率なコードに溺れているが改善方法が思いつかない人
オブジェクト指向の基礎に触れたので次のステップに進みたい人
印象に残った言葉
雑感
")
新装版 リファクタリング―既存のコードを安全に改善する― (OBJECT TECHNOLOGY SERIES)
- 作者: Martin Fowler,児玉公信,友野晶夫,平澤章,梅澤真史
- 出版社/メーカー: オーム社
- 発売日: 2014/07/26
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (11件) を見る
データベーススペシャリスト試験対策(主に午後2など)
はじめに
情報処理技術者試験のデータベーススペシャリストに合格した。
 前回は不合格(午後1が85点, 午後2が51点)で2回目の受験で合格となった。
前回は不合格(午後1が85点, 午後2が51点)で2回目の受験で合格となった。
落ちたパターンと受かったパターン両方体験する事となった。
前回、今回と別のアプローチ(設問選択)で試験に望んだので自分なりの対策方針を共有する。
筆者の環境、前提
WEBアプリケーションエンジニア
テーブルスキーマの変更やデータ操作クエリも業務で日常的に使用する。
応用情報技術者保有している。(午前1試験免除期間中)
使用参考書

- 作者: 三好康之
- 出版社/メーカー: 翔泳社
- 発売日: 2017/09/12
- メディア: 単行本(ソフトカバー)
- この商品を含むブログを見る
午前〜午後1試験対策
午後1まではとにかく数をこなすのが有効と思われる。
午後1対策のポイント
午後1は3問中2問選択する形式なので自分の苦手分野と得意分野を明確にしておいた方が当日迷わずに済む。
午後1の設問後半は少しひねっていたり難易度が上がっている場合が多いのでその部分がわからなくても焦らず、 設問前半部分の基礎的な所を落とさないようにすると十分合格圏内に届くと思われる。
時間制限が厳しめなので準備段階から時間を区切って練習する。
午後2 設問選択の分析
問1(物理設計系)を選択するか問2(データモデリング系)を選択するかで大きく方針が分かれる。
時間が有れば両方対策でファイナルアンサー
自分の感触だと以下の様になる。
問1(物理設計系)
問題との相性によって結果が大きく変わる大穴的設問。
ある程度の実務経験 or プライベートでも練習用に環境構築など行えれば勉強時間がかなり少なくても合格出来る可能性が有る。
問2(データモデリング系)
事前の準備によって結果が安定してくる本命的設問。
長文問題は読むのが大変 かつ 年度によって難易度は変わるが答え方や問うてくるポイント自体はある程度共通なので練習すればするほど得点に繋がりやすい。
採用した方針
平成29年度
練習で平成22年度と平成25年度の午後2問2*3を解いた所全然できずに心が折れた。
問1の物理設計系は平成26年〜28年あたりを解いてみたら合格ラインくらい得点できた。
問1に絞って受験した所、設問内容が相性悪め かつ 難問*4だった。。
→ 不合格
平成30年度
問1の物理設計系は運要素が強いと考えたので問2のデータモデリング系に照準を合わせて準備をする事にした。
問2は年度によって難易度が結構変わるが難しい時は他の受験者も点数は低いと思われるので基礎〜中難易度の部分を落とさない事を意識する事にした。
→ 合格!
午後2 設問選択まとめ
試験対策時間があまり確保出来ない場合は大穴狙いで問1の物理設計系を選択すると良いかもしれないよ
無難にやるなら問2のデータモデリング系をしっかりと対策した方が合格し易いよ
雑感
資格有無は業務能力に関係無いという意見も有るけど、曖昧な部分が整理されるので実用レベルまでブラッシュアップしていくか使えない知識として腐らすか、活かすも殺すもその人次第だと思う
かつてはSQL知らなくても問題選択次第で合格できたらしいけど最近は無理らしい